RAG 检索增强生成实战
RAG(Retrieval-Augmented Generation,检索增强生成)是解决大模型“知识滞后”与“幻觉”问题的核心技术,通过将“检索外部知识库”与“大模型生成”相结合,让 AI 能够基于最新、最精准的私有数据回答问题。在企业知识库问答、文档助手、垂直领域咨询等场景中,RAG 已成为落地必备方案。
一、RAG 核心原理
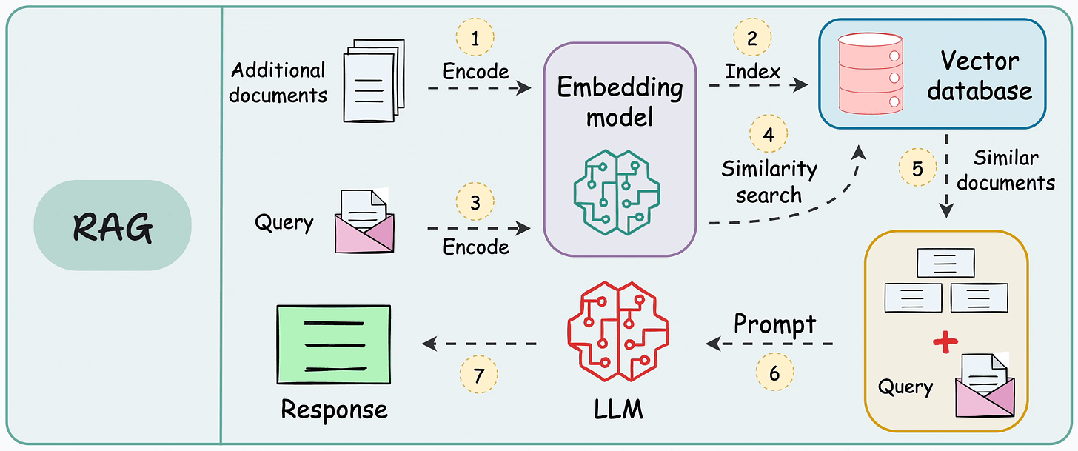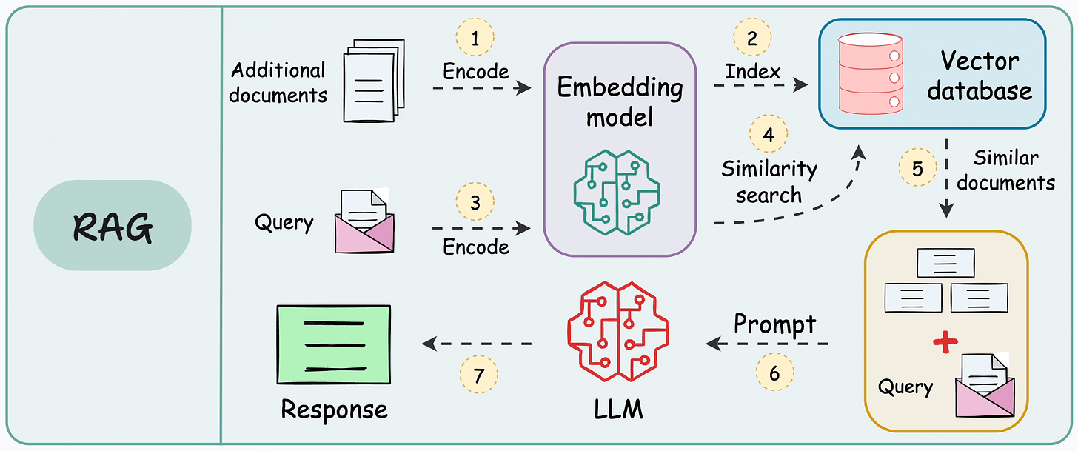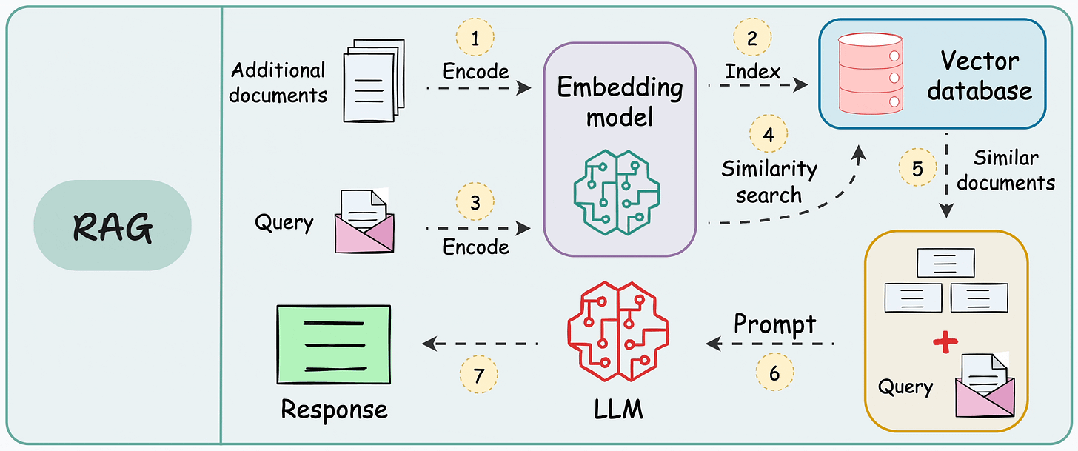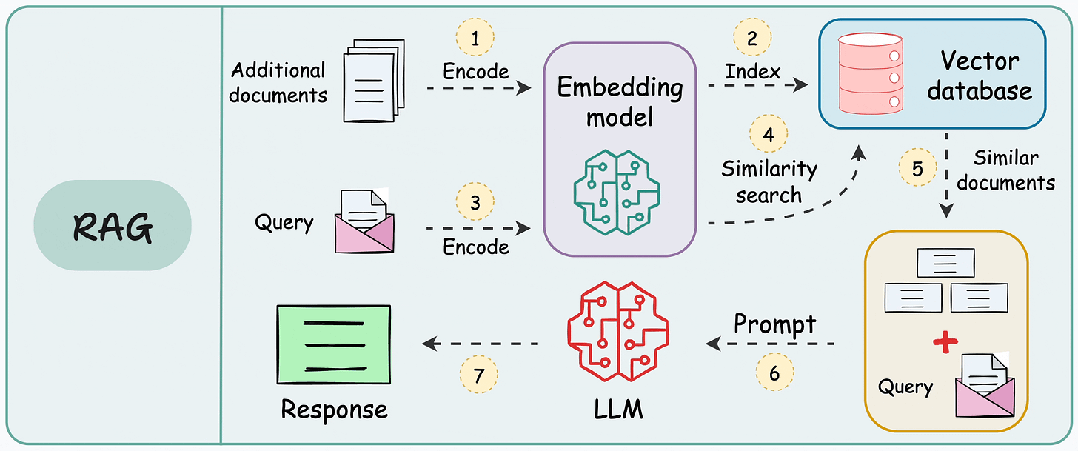
RAG 的本质是“先检索,后生成”,通过检索模块为大模型提供精准的上下文支撑,避免模型依赖过期的预训练知识或编造信息。其核心流程可分为五步:
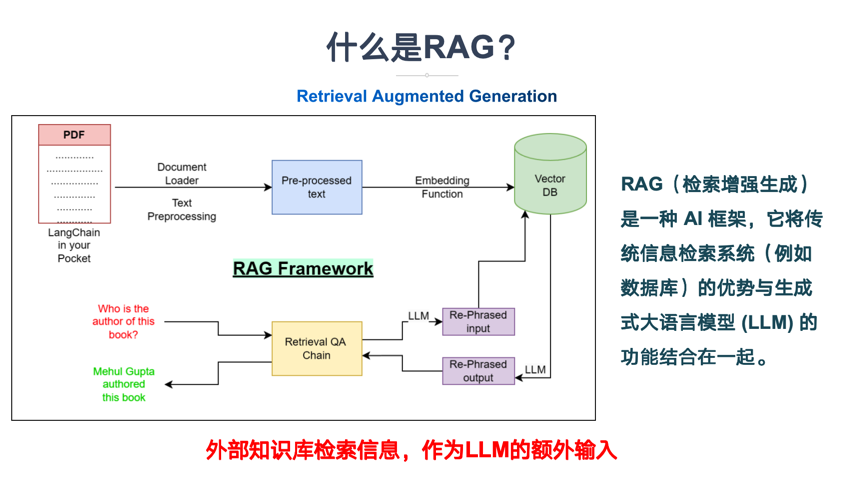
- 文档加载:导入 PDF、Word、Markdown 等格式的私有文档;
- 文档预处理:拆分文档为片段(Chunking)、提取关键信息,避免文本过长;
- 向量转换:通过嵌入模型(Embedding)将文本片段转为向量(Vector);
- 检索匹配:用户提问后,检索向量数据库中最相关的文本片段;
- 生成回答:将检索结果与提问一起传给大模型,生成精准回答。
二、RAG 技术栈选型
搭建生产级 RAG 系统,需合理选择以下核心组件:
1. 文档加载工具
- LangChain Document Loaders:支持 100+ 文档格式,适配 PDF/Word/Excel/网页等;
- Unstructured:擅长复杂格式文档解析(如多栏、图文混排 PDF)。
2. 文本拆分策略
- 按字符长度拆分:基础方案,适合普通文本(如每段 500 字);
- 按语义拆分:基于句子边界或段落,避免拆分语义单元(推荐使用 LangChain 的 RecursiveCharacterTextSplitter)。
3. 嵌入模型(Embedding)
- 开源模型:Sentence-BERT(all-MiniLM-L6-v2)、BGE,适合本地部署;
- API 模型:OpenAI Embeddings、通义千问 Embeddings,适合快速落地。
4. 向量数据库
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Pinecone | 云原生、无需运维 | 快速验证、中小规模项目 |
| Milvus | 开源、高吞吐 | 大规模私有化部署 |
| Chroma | 轻量、易部署 | 本地开发、小型项目 |
| Redis | 支持向量存储+缓存 | 已有 Redis 生态的项目 |
5. 大模型选择
- 通用场景:GPT-3.5/4、通义千问、文心一言;
- 私有化场景:Llama 2、Qwen-7B/14B(需部署本地)。
三、实战项目:企业知识库智能问答系统
以“某科技公司内部知识库问答”为例,完整实现 RAG 流程:
1. 环境搭建
python
# 安装核心依赖
pip install langchain openai pinecone-client sentence-transformers pypdf